User Manual
Basic Knowledge
Products and Services
Speech-to-Text (Speech recognition, or Auto Speech Recognition, ASR) is a service that converts audio speech into corresponding language text. By using Speech-to-Text services, you can easily and conveniently integrate speech recognition technology into your applications.
The Speech-to-Text category includes the following products: Short Speech Transcription, Real-time Speech Transcription, and Audio File Transcription.
- Short Speech Transcription: Audio data is sent to the Speech-to-Text service via HTTP request or WebSocket request. Each request only accepts audio data not exceeding 60 seconds and does not have an automatic sentence-breaking function. When using the HTTP API, the final recognition result will be returned at once; when using the WebSocket API, intermediate recognition results and final results can be received while sending data, for real-time echo.
- Real-time Speech Transcription: To transcribe audio data within a WebSocket duplex stream. The theoretical upper limit of audio duration is 37 hours, and it can automatically break sentences. Real-time Speech Transcription can receive intermediate recognition results and final results while sending data, for real-time echo.
- Audio File Transcription: An audio file (or audio URL) is sent to the Speech-to-Text service via HTTP request to create an asynchronous transcription task. After the task is created, the transcription progress can be queried through a query API, and the final transcription result can be obtained if the task ends normally. The duration of an audio file should not exceed 10 hours (and the file size must be controlled below 2 GB).
A brief comparison of each product is shown in the table below.
| Item/Product | Short Speech Transcription | Real-time Speech Transcription | Audio File Transcription |
|---|---|---|---|
| Function | To recognize short audio and return results in one go, or return results while processing. | To transcribe streaming audio and return results while processing. | To transcribe audio files into scripts or subtitles, and return results all at once after process is complete. |
| Interface Protocol | HTTP and WebSocket | WebSocket | HTTP |
| Audio Limit | 60 seconds | Theoretical upper limit of about 37 hours | 10 hours, below 2 GB |
| Supported Formats | WAV/PCM | WAV/PCM | WAV/PCM/OPUS/MP3/MP4/M4A, etc. |
| Automatic Sentence Breaking | No | Yes | Yes |
| Word Information/ITN and Other Practical Features | Yes | Yes | Yes |
| Typical Usage Scenarios | Voice Assistant | Real-time Subtitles | Audio file transcription Video subtitle generation |
Basic Terms
Sample Rate
The sample rate of an audio recording refers to the number of times the sound signal is sampled per second by the recording device. The higher the sampling frequency, the more authentic and natural the sound reproduction will be.
When using Speech-to-Text services, you can specify the sample rate of the audio, and the actual sample rate of the audio sent must be consistent with this parameter. Currently, most Speech-to-Text models only support audio with a sample rate of 16000 Hz, while a few languages such as Mandarin Chinese additionally support audio with a sample rate of 8000 Hz (requiring the selection of the corresponding model).
Sample Depth
Also known as bit depth or sample size, this parameter measures the variation in sound waves and refers to the number of binary digits used in the digital sound signal by the sound card when recording and playing sound files. Short Speech Transcription and Real-time Speech Transcription services currently only support audio with a 16-bit sample depth, while Audio File Transcription service supports other depth.
Sound Channel
Sound channel (or channel) refers to the independent audio signals that are recorded or played back at different spatial positions, so the number of sound channels is also the number of sound sources recorded or the corresponding number of speakers when played back. Short Speech Transcription and Real-time Speech Transcription services currently only support mono (single-channel) audio, while Audio File Transcription service supports both mono and multi-channel audio.
Language
The service supports multiple languages and dialects, and you can specify the language of the audio (as well as the country or regional dialect). For a complete list of supported languages, please refer to the "Language Support" section below.
Intermediate and Final Results
For WebSocket APIs (WebSocket API of Short Speech Transcription and Real-time Speech Transcription), recognition results are returned in real-time as the speech is input. For example, the sentence "天気がいいです。" might produce the following recognition results during the recognition process:
てんき
天気が
天気がいい
天気がいいです。Among them, the first three lines are referred to as "intermediate results," and the last one is called the "final result." By setting the enable_intermediate_result parameter of the Short Speech Transcription or Real-time Speech Transcription Websocket API, you can control whether to return intermediate results or not.
Note:
Non-streaming APIs (Short Speech Transcription POST API and Audio File Transcription API) do not have intermediate results; only the final result is provided.
Word Information
Word information refers to the segmentation content of the recognition results, and it is returned in the final result. You can specify whether to return word information through connection parameters.
| Item | Final Result Word Information |
|---|---|
| Control Parameter | enable_words |
| Language Support | Supports all languages |
| Includes: Text Content, Start Time, End Time | Yes |
| Includes: Word Type (Common/Punctuation/Particle/Sensitive Word) | Yes |
Inverse Text Normalization (ITN)
Inverse Text Normalization (ITN) refers to the process of displaying dates, numbers, and other objects in speech recognition results in a conventional format, as shown in the table below:
| Result without ITN | Result with ITN |
|---|---|
| 二十パーセント | 20% |
| 千二百三十四円 | 1234円 |
| 四月三日 | 4月3日 |
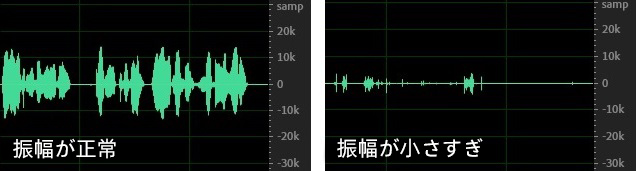
Amplitude
The amplitude of an audio signal determines the loudness of the sound. An amplitude that is too high or too low is not conducive to the effectiveness of speech recognition. The recommended amplitude is around ±10k, which can achieve the best speech recognition results. For example, the left side of the following figure shows a normal amplitude (ranging around ±10k), while the right side has a too low amplitude (ranging around ±1k), thus the speech recognition effect in the right figure will be affected.
For cases with low amplitude, improvements can be made from two aspects: first, by adjusting the recording method, such as the distance between the person and the microphone, microphone/recording parameter settings, etc., to address the issue of low volume at the original audio level; second, by using the amplitude gain parameter gain in the Speech-to-Text service to amplify the original audio amplitude, and then proceed with speech recognition processing.
Practical Features
Inverse Text Normalization (ITN)
When using speech recognition services, you can specify whether to enable ITN by configuring the enable_inverse_text_normalization parameter.
Hotwords Optimization
For some unique names, places, product names, company names, or specialized vocabulary in certain fields, there may be a lower recognition accuracy. For these specialized terms, you can manually add them as "hotwords", and by configuring the hotwords_id parameter with the hotwords' ID during recognition, you can significantly improve the recognition accuracy of the terms in the hotword list. For operations such as adding or deleting hotwords, please refer to the "Speech-to-Text Service Hotword API Protocol."
When using hotwords, you can specify the weight of the hotwords by using hotwords_weight. The higher the weight is, the higher the recognition accuracy of the terms in the hotword list, but it may also increase the probability of misrecognizing other similar-sounding words, so it is necessary to balance the configuration of the weight parameter.
Forced Correction (Forced Replacement)
For recognition errors that cannot be resolved by hotword optimization, you can use the forced replacement feature to manually correct specified incorrect words. For example, if the speech recognition service mistakenly recognizes "5G" as "五時," you can manually add a forced replacement rule of "五時→5G" and configure the correction_words_id parameter with the ID during recognition to achieve correct recognition. For operations such as adding or deleting forced correction words, please refer to the "Speech-to-Text Service Forced Correction API Protocol."
Forbidden Words Filtering
For words or phrases that you do not wish to display directly, you can manually add them as "forbidden words." By configuring the forbidden_words_id parameter with the forbidden words' ID during recognition, the sensitive words in the recognition results (including intermediate and final results) will be automatically replaced with a specified character (default is an asterisk * , which can be set to other characters through the service.toml configuration file). For operations such as adding or deleting forbidden words, please refer to the "Speech-to-Text Service Forbidden Word API Protocol."
Filler Word Removal
For common colloquial expressions such as "えっと", "えー", "まあ" etc., you can manually add filler word removal rules. By enabling the enable_modal_particle_filter parameter during recognition, the matching filler words can be automatically removed from the recognition results (only the final results).
Configuration Method
In the model directory, there is a file named modal_particle.txt, where you can add filler word removal rules. Each rule should be written on a new line using regular expressions. After modifying the filler word removal rules, you need to restart the service for the changes to take effect.
File Path:
- For Short Speech Transcription/Real-time Speech Transcription:
asr-integrated/model/asr/{lang_type}/post/modal_particle.txt- For Audio File Transcription:
asr-integrated/model/asr-file/{lang_type}/post/modal_particle.txt
Note
The internal processing order for the above features is as follows:
Amplitude Gain
For situations where the recording volume (amplitude) is too low and affects the speech recognition effect, you can use the gain parameter to adjust the amplitude gain. The system will internally amplify the original audio amplitude and then perform speech recognition processing.
Streaming Media Protocol Support
Real-time Speech Transcription supports using RTSP audio and video streams as the audio source for speech recognition. The system will pull the stream and perform speech recognition processing on the voice data within it. Currently, it supports audio formats encoded in AAC.
Post-Speech Silence Detection
Short Speech Transcription supports the activation of post-speech silence detection. Once a threshold max_suffix_silence is set, the recognition will automatically end if the silence duration at the end of a sentence exceeds this threshold.
Speech Recognition Confidence Score
Short Speech Transcription (WebSocket API), Real-time Speech Transcription, and Audio File Transcription (script format) support the return of speech recognition confidence scores, indicating the system's certainty or trust in the recognition results. The higher the confidence score is, the more confident the system is in determining that the returned recognition results are an accurate transcription of the user's spoken content.
Audio File Transcription Output Formats
For the audio file transcription service, the output format can be configured using the output parameter.
- Script format: Suitable for long texts such as manuscripts, with normal punctuation based on pauses in speech.
- Subtitle format: Optimized for subtitles, with shorter sentences and no punctuation at the end of sentences.
Speech Speed Calculation in Audio File Transcription
The system will automatically calculate the average speech speed. For Japanese, Chinese, and Korean, the unit is characters per minute. For English, the unit is words per minute.
Return of Volume Value
Short Speech Transcription (WebSocket API), Real-time Speech Transcription, and Audio File Transcription support the return of volume values (ranging from 0 to 100). The volume values are returned with intermediate and final results per sentence and can be used for UI display (such as a volume bar).
Speaker Diarization
In the audio file transcription process, the speaker diarization feature allows for the identification and differentiation of various speakers while transcribing the audio content, returning speaker identifiers in the recognition results. You can manually specify the number of speakers or let the system automatically determine the number of participants. This feature requires the selection of the voiceprint component (module_vpr), which only supports Linux x86 platform.
Multilingual Speech with English Mixing and Language Tagging
To meet users' communication needs in different language environments, the system supports mixed English speech, with the release of models for mixed Japanese-English and Mandarin-English speech. The mixed speech models can recognize dialogues that freely switch between the primary language and English, greatly enhancing the communication efficiency for multilingual users.
Before starting speech recognition, set enable_lang_label = true, and the system will automatically break sentences and return the language code in the lang_type parameter when switching languages.
Automatic Segmentation
The system supports setting the paragraph_condition parameter as the condition for paragraph segmentation based on character count. When the set character count is reached, a new paragraph number will be returned at the beginning of the next sentence.
Audio Encoding
Currently, the speech recognition products support the following audio encoding formats. Please set the format field to the corresponding encoding format.
Note:
At present, the audio formats supported by Short Speech Transcription and Real-time Speech Transcription are mono format. Audio File Transcription supports both mono and multi-channel formats.
| Encoding Format | Description | One-Sentence Recognition / Real-Time Speech Transcription | Audio File Transcription |
|---|---|---|---|
| pcm | Uncompressed audio with a sample width of 16 bit, Little-Endian. Common in regular uncompressed WAV formats (excluding the first 44 bytes of WAV header). | √ | √ |
| wav | Audio with a sample width of 16 bit. | √ | √ |
| opus | OPUS format encapsulated in an OGG container, with a framesize of at least 60 ms. | √ | |
| mp3 | √ | ||
| mp4 | √ | ||
| m4a | √ | ||
| amr | √ | ||
| 3gp | √ | ||
| aac | √ Supported for Real-time Speech Transcription RTSP streaming | √ |
Language Support
Currently, the speech recognition products support the following languages (requiring the selection of the corresponding language model). Please set the lang_type (or langType, depending on the actual SDK used) field to the appropriate language code.
| Language | Language Code | Description |
|---|---|---|
| Japanese | ja-JP | Equipped with the option for mixed Japanese-English speech |
| English | en-US | |
| Chinese (Mandarin) | zh-cmn-Hans-CN | Equipped with the option for mixed Chinese-English speech |
| Korean | ko-KR |