音声認識サービス使用マニュアル
基本知識
プロダクトとサービス
音声認識は、音声を対応する言語のテキストに変換するサービスです。音声認識サービスを利用することで、音声認識技術をアプリケーションに簡単に統合できます。
音声認識の種類には、一発話認識、リアルタイム音声認識、録音ファイル書き起こしがあります。
- 一発話認識:音声データをHTTPリクエストボディまたはWebSocketリクエストとして音声認識サービスに送信します。各リクエストで受け付ける音声データは60秒以内で、自動句読機能はありません。HTTP方式では、最終認識結果が一括で返されます。WebSocket方式では、データ送信と同時に中間認識結果および最終認識結果が返され、リアルタイムの表示に使用されます。
- リアルタイム音声認識:WebSocketデュプレックスストリーム内の音声データを認識し、音声の長さに制限はなく、自動句読機能があります。リアルタイム音声認識では、データ送信と同時に中間認識結果および最終認識結果が返され、リアルタイムの表示に使用されます。
- 録音ファイル書き起こし:音声ファイルをHTTPリクエストボディとして音声認識サービスに送信し、非同期書き起こしタスクを作成します。タスク作成後、クエリインターフェースを介して書き起こしの進捗を確認できます。タスクが正常に終了すると、最終の書き起こし結果を取得できます。録音ファイルは最長10時間(ファイルサイズは2 GB以下)までです。
各製品の簡単な比較は以下の表のとおりです:
| 項目/プロダクト | 一発話認識 | リアルタイム音声認識 | 録音ファイル書き起こし |
|---|---|---|---|
| 機能 | 短い音声を認識し、一括で認識結果を返す、または認識しながら結果を返す。 | ストリーミング音声を認識し、認識しながら結果を返す。 | 長い音声ファイルを文書または字幕に書き起こし、認識完了後に一括で結果を返す。 |
| インターフェースプロトコル | HTTP、WebSocket | WebSocket | HTTP |
| 音声制限 | 60秒 | 無制限 | 10時間、2 GB以下 |
| 対応形式 | WAV/PCM | WAV/PCM | WAV/PCM/OPUS/MP3/MP4/M4Aなど |
| 自動句読 | 無し | 有り | 有り |
| 単語情報/ITN等の便利な機能 | 有り | 有り | 有り |
| 典型的な使用シーン | 音声アシスタント | リアルタイム字幕 | 音声ファイルの書き起こし 動画字幕生成 |
基本用語
サンプリングレート(sample rate)
音声サンプリング率は、音声信号をサンプリングする回数を示しており、1秒間に何回サンプリングされるかを表しています。サンプリングレートが高いほど、音声のデータより詳しく保存され、もっと精度の認識率が期待されます。
弊社音声認識各サービスを使用する際には、パラメータとして音声のサンプリング率を指定し、実際に送信される音声のサンプリング率はパラメータ値と一致する必要があります。現在、音声認識の各サービスはほとんどの言語で16000 Hzのサンプリングレートの音声をサポートしています。中国語(普通話)など一部の言語は8000 Hzのサンプリングレートの音声もサポートしています(対応モデルの選択が必要です)。
サンプルサイズ(sample size)
サンプルサイズは、音声の波動変化を評価するパラメータであり、音声ファイルを収集および再生する際に使用されるデジタル音声信号の二進制数です。弊社音声認識各サービスは、現在16ビットのサンプルサイズのみサポートしています。
音声チャンネル(sound channel)
チャンネルとは、録音または再生時に異なる空間位置で収集または再生される独立した音声信号を指します。したがって、チャンネル数は音声を録音する際の音源の数または再生時の対応するスピーカーの数を表します。一発話認識およびリアルタイム音声認識サービスは現在、モノラル(シングルチャンネル)音声のみをサポートしており、録音ファイル書き起こしサービスはモノラルまたはマルチチャンネル音声をサポートしています。
言語
サービスは複数の言語と方言をサポートしており、音声の言語(および国または地域の方言)を指定できます。対応言語の完全なリストは、以下の「言語サポート」セクションを参照してください。
中間結果と最終結果
ストリーミングインターフェース(一発話認識WebSocketインターフェース、リアルタイム音声認識)では、音声の入力に伴い、認識結果がリアルタイムで返されます。例えば、「今日は天気がいいです」という文の場合、認識プロセス中に以下の認識結果が生成される可能性があります:
てんき
天気が
天気がいい
天気がいいです。これらのうち、最初の三行は「中間結果」と呼ばれ、最後の一行は「最終結果」と呼ばれます。一発話認識またはリアルタイム音声認識のストリーミングインターフェースのenable_intermediate_resultパラメータを設定することで、中間結果を返すかどうかを制御できます。
注意:
非ストリーミングインターフェース(一発話認識POSTインターフェース、録音ファイル書き起こし)には中間結果がなく、最終結果のみがあります。
セグメント情報
セグメンタ情報は、認識処理中でセグメント別の情報であり、中間結果と最終結果の情報に分けられます。接続パラメータを使用して、セグメント情報を返すかどうかを指定できます。
| 項目 | 中間結果のセグメント情報 | 最終結果のセグメント情報 |
|---|---|---|
| 制御パラメータ | enable_intermediate_words | enable_words |
| 対応言語 | 中国語関連(言語コードがzhで始まるもの)のみ対応 | すべての言語をサポート |
| テキスト内容、開始時間、終了時間を返すかどうか | √ | √ |
| 単語タイプ(一般/句読点/感嘆詞/NG単語)を返すかどうか | × | √ |
| 単語安定性ステータスを返すかどうか | √ | × |
単語安定性ステータスは、中間結果の単語が変更される可能性があるかどうかを示します。値がfalseの場合、その単語は後続の中間結果で変更される可能性があります。逆に、値がtrueの場合、その単語は安定しており、変更されることはありません。
逆テキスト標準化(ITN)
逆テキスト標準化(Inverse Text Normalization)は、音声認識結果の中の日時や数字などを慣用の形式で表示することを指します。例えば、以下のようになります:
| ITNが無効な結果 | ITNが有効な結果 |
|---|---|
| 二十パーセント | 20% |
| 千二百三十四円 | 1234円 |
| 四月三日 | 4月3日 |
振幅
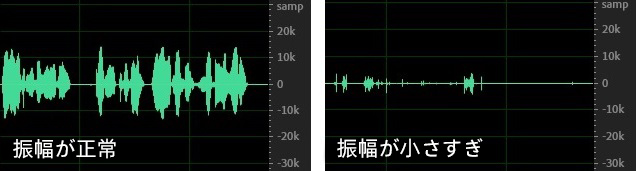
音声の振幅は音量の大きさを決定します。振幅が大きすぎるまたは小さすぎると、音声認識の効果が低下します。推奨振幅は±10k前後で、この範囲であれば音声認識の最適な効果を得ることができます。以下の図に示すように、左側は正常な振幅(±10k前後の範囲)であり、右側は振幅が小さすぎる(±1k前後の範囲)ため、右側の音声の認識効果は低下します。
振幅が小さい場合、次の2つの方法で改善できます。一つは録音方法の調整です。例えば、マイクとの距離、マイク/録音パラメータの設定など、元の音声層で音量が低い問題を解決します。もう一つは、音声認識サービスの振幅ゲインパラメータgainを使用して、元の音声の振幅を増幅してから音声認識処理を行います。
実用機能
逆テキスト標準化(ITN)
音声認識サービスを利用する際に、enable_inverse_text_normalizationパラメータを設定することで、ITNを有効にするかどうかを指定できます。
単語エンハンス
固有の人名、地名、製品名、会社名または特定分野の専門用語など、認識精度が低い場合があります。これらの専門用語を「単語」として単語辞書に登録することができ、認識時にhotwords_idパラメータで単語辞書IDを指定することで、リスト内の単語の認識精度を大幅に向上させることができます。単語の追加/削除に関する操作は、「音声認識サービス単語インターフェースプロトコル」を参照してください。この機能は日本語・英語・中国語(普通話)のみ対応しています。
単語辞書を使用する際には、重みを指定できます。重みが大きいほど、リスト内の単語の認識精度が高くなりますが、同時に他の類似語彙の誤認識の可能性も高くなるため、重みパラメータの設定に注意が必要です。
文書エンハンス(単語辞書自動作成)
単語辞書を新規登録または変更する際に、指定された文書から人名、地名、機関名などのキーワードを自動的に抽出し、単語として文書エンハンスすることができます。この機能は中国語(普通話)のみ対応しています。
強制置換
単語エンハンスでも解決できない認識の誤りに対して、強制置換機能を使用して特定の単語を手動で修正できます。例えば、音声認識サービスが「5G」を「五時」と誤認識する場合、「五時→5G」という強制置換ルールを手動で追加し、認識時にcorrection_words_idパラメータで強制置換辞書IDを指定することで正しい認識を実現できます。強制置換文字の追加/削除に関する操作は、「音声認識サービス強制置換インターフェースプロトコル」を参照してください。
NG単語フィルター
直接表示したくない言葉や単語については、「NG単語」としてNG単語辞書に登録することができます。認識時にforbidden_words_idパラメータでNG単語辞書IDを指定することで、認識結果(中間結果と最終結果)内のNG単語を自動的に指定文字(デフォルトはアスタリスク*、service.toml設定ファイルで他の文字に変更可能)に置き換えることができます。NG単語の追加/削除に関する操作は、「音声認識サービスNG単語インターフェースプロトコル」を参照してください。この機能は英語・中国語のみ対応しています。
言い淀みフィルター
言い淀みにおける「えっと」「えー」「まあ」などの口癖については、言い淀みのフィルタールールを登録できます。認識時にenable_modal_particle_filterパラメータを設定して言い淀みフィルターを有効にすると、認識結果(最終結果のみ)から一致する口癖を自動的に削除できます。
設定方法
モデルディレクトリ内にmodal_particle.txtがあり、このファイルに言い淀みのフィルター規則を追加できます。各規則は1行ごとに記述し、正規表現形式を使用します。規則を変更した後、サービスを再起動する必要があります。
ファイルパス:
- 一発話認識/リアルタイム音声認識:
asr-integrated\asr\{lang_type}\post\modal_particle.txt- 録音ファイル書き起こし:
asr-integrated\asr-file\{lang_type}\post\modal_particle.txt
注意
上記の機能の内部処理順序は次のとおりです:
振幅ゲイン
録音音量(振幅)が小さく、音声認識の効果が低下する場合、gainパラメータを使用して振幅ゲインを調整できます。システムは内部で元の音声の振幅を増幅してから音声認識処理を行います。
ストリーミングプロトコル対応
リアルタイム音声認識は、RTSP音声ビデオストリームを音声認識の音声源として使用することをサポートします。システムはストリームを取得し、音声データを音声認識処理します。現在、AACエンコード形式の音声をサポートしています。
ネットワークサウンドカード対応
Linuxプラットフォームだけで対応
リアルタイム音声認識は、ネットワークサウンドカード(Network Sound Card/Audio Network Interface)を音声認識の音声源として使用することをサポートします。システムは指定されたサウンドカードとチャンネル番号から単一または複数の音声を取得し、音声認識処理を行い、認識結果にチャンネル番号も返します。
使用前にservice.tomlファイルでethnameパラメータを設定する必要があります。パラメータ値はネットワークカードの名称です(ip aコマンドを使用して本機のすべてのネットワークカードを確認できます)。
文末句読点の当文追加/後続追加
言語コードが
zhで始まる中国語関連の言語については、デフォルトで後続追加の句読点ロジックを有効にします。service.toml設定ファイルのpunctuateLaterパラメータでこのロジックを有効にするかどうかを制御できます。
リアルタイム音声認識には、2つの文末句読点追加ロジックがあります:
- 当文追加:最終結果(SentenceEndイベント)で文末句読点を返します。しかし、この場合、次の文のテキスト情報が不足しているため、句読点が正確でない可能性があります。
- 後続追加:現在の文末の句読点は、前後の文を総合的に判断して、次の文の文頭で返されます。これにより、文末句読点の正確性が向上します。この機能は、言語コードが
zhで始まる中国語関連の言語のみ対応しています。
音声後置無音検出
一発話認識は、音声後置無音検出機能を有効にすることをサポートします。しきい値を設定すると、文末の無音時間がしきい値を超えると自動的に認識が終了します。
音声認識結果の信頼度
一発話認識(ストリーミングインターフェース)、リアルタイム音声認識、録音ファイル書き起こし(文書形式)は、音声認識結果の信頼度を返すことをサポートします。信頼度は、システムが認識結果の確定性または信頼度を示します。信頼度が高いほど、システムが返した認識結果がユーザーの発言内容を正確に書き起こしたと確信しています。
録音ファイル書き起こしの出力形式
録音ファイル書き起こしサービスについて、outputパラメータを使用して出力形式を設定できます。
- 文書形式:長文テキストに適しており、話者の停頓に基づいて通常の句読を行います。
- 字幕形式:字幕用に最適化された出力であり、句読結果が短く、文末に句読点がありません。
録音ファイル書き起こしのキーワード自動抽出
録音ファイルをアップロードする際に、キーワード数の上限を指定すると、システムは指定された数を超えない範囲でキーワードを自動抽出し、関連性や単語頻度に基づいて並べ替えることができます。この機能は中国語のみ対応しています。
録音ファイル書き起こしの話す速度計算
平均の話す速度を自動計算します。日本語・中国語・韓国語の場合、単位は字/分です。英語の場合、単位は単語/分です。
英語混合発話と言語ラベル
異なる言語環境でのコミュニケーションニーズを満たすために、システムは英語混合発話をサポートしており、現在、日英混合発話・中英混合発話のモデルが提供されています。混合発話モデルは、主言語と英語の間で自由に切り替える会話を認識し、多言語使用者のコミュニケーション効率を大幅に向上させます。
音声認識を開始する前にenable_lang_label = trueを設定すると、言語を切り替える際に自動的に句読され、lang_typeパラメータで言語コードが返されます。
自動段落分け
段落の字数条件としてparagraph_conditionパラメータを設定することをサポートします。音声認識結果が指定された文字数に達すると、次の文で新しい段落番号を返します。
音声コーディング
現在、音声認識の各プロダクトは以下の音声コーディング形式をサポートしています。formatフィールドを対応するコーディング形式に設定してください。
注意:
現在、一発話認識およびリアルタイム音声認識はモノラル(mono)形式の音声をサポートしています。録音ファイル書き起こしはモノラル、マルチチャンネル形式をサポートしています。
| コーディング形式 | 説明 | 一発話認識、リアルタイム音声認識 | 録音ファイル書き起こし |
|---|---|---|---|
| mpcm | 非圧縮の16ビット、リトルエンディアンの音声。通常の非圧縮WAV形式(最初の44バイトのWAVヘッダーを含まない)に一般的です。 | ○ | ○ |
| wav | 16ビットの音声。 | ○ | ○ |
| opus | OGGコンテナに封入されたOPUS形式で、フレームサイズは少なくとも60ms。 | ○ | |
| mp3 | ○ | ||
| mp4 | ○ | ||
| m4a | ○ | ||
| amr | ○ | ||
| 3gp | ○ | ||
| aac | △ リアルタイム音声認識RTSPストリーム対応 | ○ |
言語サポート
言語コードは、language-variant-script-region形式を採用しています。
- language:言語(ISO 639-1)、全小文字、例:日本語はja、英語はen
- variant(オプション):発音または方言(ISO 639-3)、全小文字、例:中国語普通話はcmn、広東語はyue
- script(オプション):書記変種(ISO 15924)、頭文字が大文字、例:簡体字はHans、繁体字はHant
- region:言語の使用地理地域(ISO 3166)、全大文字、例:日本はJP、中国本土はCN
現在、音声認識の各プロダクトは以下の言語をサポートしています(対応する言語モデルの選択が必要です)。lang_type(またはlangType、実際に使用するSDKによって決まります)フィールドを対応する言語コードに設定してください。
| カテゴリー | 名称 | 言語コード | 一発話認識、リアルタイム音声認識 | 録音ファイル書き起こし | 備考 |
|---|---|---|---|---|---|
| 日本語 | 日本語 | ja-JP | √ | √ | 日英混合発話モデルを選択可能 |
| 中国語と方言 | 中国語(普通話) | zh-cmn-Hans-CN | √ | √ | 中英混合発話モデルを選択可能 |