Cloud API
Short Speech Recognition Cloud API
1 Feature Introduction
Short Speech Recognition: Speech recognition for short audio clips under 60 seconds, suitable for conversational chat, control commands, and other short speech recognition scenarios.
2 WebSocket API (Streaming)
2.1 Request URL
wss://api.voice.dolphin-ai.jp/v1/asr/ws2.2 Interaction Process
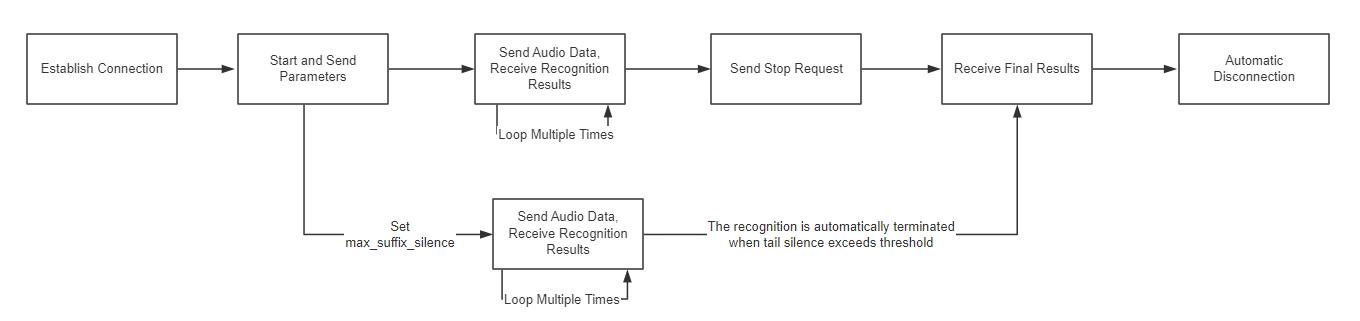
1. Authorization
When the client establishes a WebSocket connection with the server, the following request header need to be set:
| Name | Type | Required | Description |
|---|---|---|---|
| Authorization | String | Yes | Standard HTTP header for setting authorization information. The format must be the standard "Bearer <Token>"form (note the space after "Bearer") |
For authorization-related operations, please refer to Authorization and Access Permissions.
2. Start and Send Parameters
The client initiates a short speech recognition request, and the server confirms the validity of the request. Parameters must be set within the request message and sent in JSON format .
Request parameters (header object):
| Parameter | Type | Required | Description |
|---|---|---|---|
| namespace | String | Yes | The namespace to which the message belongs: SpeechRecognizer indicates short speech recognition |
| name | String | Yes | Event name: StartRecognition indicates the start phase |
Request parameters (payload object):
| Parameter | Type | Required | Description | Default Value |
|---|---|---|---|---|
| lang_type | String | Yes | Language option, refer to Developer Guides - Language Support | Required |
| format | String | No | Audio encoding format, refer to Developer Guides - Audio Encoding | pcm |
| sample_rate | Integer | No | Audio sampling rate, refer to Developer Guides - Basic Terms When sample_rate=‘8000’ field parameter field is required, and field=‘call-center’ | 16000 |
| enable_intermediate_result | Boolean | No | Whether to return intermediate recognition results | true |
| enable_punctuation_prediction | Boolean | No | Whether to add punctuation in post-processing | true |
| enable_inverse_text_normalization | Boolean | No | Whether to perform ITN in post-processing, refer to Developer Guides - Basic Terms | true |
| max_sentence_silence | Integer | No | Speech sentence breaking detection threshold. Silence longer than this threshold is considered as a sentence break. The valid parameter range is 200~1200. Unit: Milliseconds | sample_rate=16000:800 sample_rate=8000:250 |
| enable_words | Boolean | No | Whether to return word information, refer to Developer Guides - Basic Terms | false |
| enable_intermediate_words | Boolean | No | Whether to return intermediate result word information, refer to Developer Guides - Basic Terms | false |
| enable_modal_particle_filter | Boolean | No | Whether to enable modal particle filtering, refer to Developer Guides - Practical Features | true |
| hotwords_list | List<String> | No | One-time hotwords list, effective only for the current connection. If both hotwords_list and hotwords_id parameters exist, hotwords_list will be used. Up to 100 entries can be provided at a time. refer to Developer Guides - Practical Features | None |
| hotwords_id | String | No | Hotwords ID, refer to Developer Guides - Practical Features | None |
| hotwords_weight | Float | No | Hotwords weight, the range of values [0.1, 1.0] | 0.4 |
| correction_words_id | String | No | Forced correction vocabulary ID, refer to Developer Guides - Practical Features Supports multiple IDs, separated by a vertical bar |; all indicates using all IDs. | None |
| forbidden_words_id | String | No | Forbidden words ID, refer to Developer Guides - Practical Features Supports multiple IDs, separated by a vertical bar |; all indicates using all IDs. | None |
| field | String | No | Field general: supports the sample_rate of 16000Hz call-center: supports the sample_rate of 8000Hz | None |
| audio_url | String | No | Returned audio format (stored on the platform for only 30 days) mp3: Returns a url for the audio in mp3 format pcm: Returns a url for the audio in pcm format wav: Returns a url for the audio in wav format | None |
| connect_timeout | Integer | No | Connection timeout (seconds), range: 5-60 | 10 |
| gain | Integer | No | Amplitude gain factor, range [1, 20], refer to Developer Guides - Practical Features 1 indicates no amplification, 2 indicates the original amplitude doubled (amplified by 1 times), and so on | sample_rate=16000:1 sample_rate=8000:2 |
| max_suffix_silence | Float | No | Post-speech silence detection threshold (in seconds), with a range of 0 to 10 seconds. If the duration of silence at the end of a sentence exceeds this threshold, recognition will automatically stop When the parameter value is set to 0 or the parameter is not provided, the post-speech silence detection feature is disabled. Special case: If set to -1, recognition will stop immediately when the speech ends. | 0 |
| user_id | String | No | Custom user information, which will be returned unchanged in the response message, with a maximum length of 36 characters | None |
| enable_save_log | Boolean | No | Provide log of audio data and recognition results to help us improve the quality of our products and services. | true |
| duration | Integer | No | Maximum Audio Duration Input: Default value: 60s. Valid range: [60, 600], unit: second. | 60 |
| enable_spoken | Boolean | No | When enabled, the sentence information will increase the return of pronunciation. Note: This feature currently only supports Japanese and is not available for other languages. | false |
| enable_dynamic_break | Boolean | No | When enabled, it will adaptively adjust the sentence-breaking effect based on the speaking rate and the maximum silence duration parameter max_sentence_silence. | false |
Example of a request:
{
"header": {
"namespace": "SpeechRecognizer",
"name": "StartRecognition"
},
"payload": {
"lang_type": "zh-cmn-Hans-CN",
"format": "wav",
"sample_rate": 16000,
"enable_intermediate_result": true,
"enable_punctuation_prediction": true,
"enable_inverse_text_normalization": true,
"max_sentence_silence": 800,
"enable_words":true
}
}Response parameters (header object):
| Parameter | Type | Description |
|---|---|---|
| namespace | String | The namespace to which the message belongs: SpeechRecognizer indicates short speech recognition |
| name | String | Event name: RecognitionStarted indicates the start phase |
| status | String | Status code |
| status_text | String | Status code description |
| task_id | String | The globally unique ID for the task; please record this value for troubleshooting |
Example of a response:
{
"header":{
"namespace":"SpeechRecognizer",
"name":"RecognitionStarted",
"app_id":"f0b4b131-362b-4d60-afd9-19c738986ed0",
"status":"000000",
"status_text":"success",
"task_id":"0220a729ac9d4c9997f51592ecc83847",
"message_id":""
},
"payload":{
"index":0,
"time":0,
"begin_time":0,
"speaker_id":"",
"result":"",
"words":null
}
}3. Send Audio Data and Receive Recognition Results
Send audio data in a loop and continuously receive recognition results. It is recommended to send data packets of 7680 Bytes each time.
Recognition results are divided into "intermediate results" and "final results". For details, refer to Developer Guides - Basic Terms.
- If
enable_intermediate_resultis set totrue, the server will return multipleRecognitionResultChangedmessages, i.e., intermediate recognition results. - If
enable_intermediate_resultis set tofalse, the server will not return any messages for this step.
RecognitionCompleted event as the final recognition result.Response parameters (header object):
| Parameter | Type | Description |
|---|---|---|
| namespace | String | The namespace to which the message belongs, SpeechRecognizer indicates short speech recognition |
| name | String | Message name, RecognitionResultChanged indicates the intermediate recognition result |
| status | Integer | Status code, indicating whether the request was successful, refer to the service status codes |
| status_text | String | Status message |
| task_id | String | The globally unique ID for the task; please record this value for troubleshooting |
| message_id | String | The ID for this message |
Response parameters (payload object):
| Parameter | Type | Description |
|---|---|---|
| index | Integer | Always 1 for short speech recognition |
| time | Integer | The duration of the currently processed audio, in milliseconds |
| begin_time | Integer | The start time of the current sentence, in milliseconds |
| speaker_id | String | Always null for short speech recognition |
| result | String | The recognition result of this sentence |
| confidence | Float | The confidence level of the current result, in the range [0, 1]. |
| words | List<Word> | Always null, intermediate results do not include word information |
Example of a response:
{
"header": {
"namespace": "SpeechRecognizer",
"name": "RecognitionResultChanged",
"status": "000000",
"status_text": "success",
"task_id": "0220a729ac9d4c9997f51592ecc83847",
"message_id": "43u134hcih2lcp7q1c94dhm5ic2op9l2"
},
"payload": {
"index": 1,
"time": 1920,
"begin_time": 0,
"speaker_id": "",
"result": "优化",
"words": []
}
}4. Stop and Retrieve Final Results
The client sends a request to stop short speech recognition, notifying the server that the transmission of audio data has ended and to terminate speech recognition. The server returns the final recognition result and then automatically disconnects the connection.
Request parameters (header object):
| Parameter | Type | Description |
|---|---|---|
| namespace | String | The namespace to which the message belongs, SpeechRecognizer indicates short speech recognition |
| name | String | Message name, StopRecognition indicates terminating recognition |
Example of a request:
{
"header": {
"namespace": "SpeechRecognizer",
"name": "StopRecognition"
}
}Response parameters (header object):
| Parameter | Type | Description |
|---|---|---|
| namespace | String | The namespace to which the message belongs, SpeechRecognizer indicates short speech recognition |
| name | String | Message name, RecognitionCompleted indicates that the recognition is completed |
| status | Integer | Status code, indicating whether the request was successful, see service status codes |
| status_text | String | Status message |
| task_id | String | The globally unique ID for the task; please record this value for troubleshooting |
| message_id | String | The ID for this message |
Response parameters (payload object):
| Parameter | Type | Description |
|---|---|---|
| index | Integer | Always 1 for short speech recognition |
| time | Integer | The duration of the currently processed audio, in milliseconds |
| begin_time | Integer | The start time of the current sentence, in milliseconds |
| speaker_id | String | Always null for short speech recognition |
| result | String | The recognition result of this sentence |
| confidence | Float | The confidence level of the current result, in the range [0, 1]. |
| words | List<Word> | Final result word information for this sentence, only returned if enable_words is set to true. |
Within it, the word information words object:
| Parameter | Type | Description |
|---|---|---|
| word | String | Text |
| start_time | Integer | The start time of the word, in milliseconds |
| end_time | Integer | The end time of the word, in milliseconds |
| type | String | Typenormal indicates regular text, modal indicates modal particles (not returned if enable_modal_particle_filter is set to true), punc indicates punctuation marks |
Example of a response:
{
"header": {
"namespace": "SpeechRecognizer",
"name": "RecognitionCompleted",
"status": "00000",
"status_text": "success",
"task_id": "0220a729ac9d4c9997f51592ecc83847",
"message_id": "45kbrouk4yvz81fjueyao2s7y7o6gjz6"
},
"payload": {
"index": 1,
"time": 5292,
"begin_time": 0,
"speaker_id": "",
"result": "优化和改进外商投资房地产管理。",
"confidence": 1,
"words": [{
"word": "优化",
"type": "normal",
"start_time": 390,
"end_time": 1110,
}, {
"word": "和",
"type": "normal",
"start_time": 1110,
"end_time": 1440
}, {
"word": "改进",
"type": "normal",
"start_time": 1440,
"end_time": 2130
}, {
"word": "外商投资",
"type": "normal",
"start_time": 2160,
"end_time": 3570
}, {
"word": "房地产",
"type": "normal",
"start_time": 3600,
"end_time": 4290
}, {
"word": "管理",
"type": "normal",
"start_time": 4290,
"end_time": 4860
},{
"word": "。",
"type": "punc",
"start_time": 4290,
"end_time": 4860
}]
}
}3 HTTP API (Non-Streaming)
3.1 HTTP Request Line
| Protocol | URL | Method |
|---|---|---|
| HTTP | https://api.voice.dolphin-ai.jp/v1/asr/api | POST |
3.2 Request Headers
HTTP request headers are composed of "key/value" pairs, with each line containing one pair. The key and value are separated by an English colon (:). The settings are as follows:
| Name | Type | Required | Description |
|---|---|---|---|
| Authorization | String | Yes | Standard HTTP header for setting authorization information. The format must be the standard "Bearer <Token>" form (note the space after "Bearer"). |
3.3 Request Parameters
The client sends a speech recognition request, and parameters are set within the request query parameters. The meanings of the parameters are as follows:
| Parameter | Type | Required | Description | Default Value |
|---|---|---|---|---|
| lang_type | String | Yes | Language option, refer to Developer Guides - Language Support | Required |
| format | String | No | Audio encoding format, refer to Developer Guides - Audio Encoding | pcm |
| sample_rate | Integer | No | Audio sampling rate, refer to Developer Guides - Basic Terms When sample_rate='8000' field parameter field is required, and field='call-center' | 16000 |
| enable_punctuation_prediction | Boolean | No | Whether to add punctuation in post-processing | true |
| enable_inverse_text_normalization | Boolean | No | Whether to perform ITN in post-processing, refer to Developer Guides - Basic Terms | true |
| enable_modal_particle_filter | Boolean | No | Whether to enable modal particle filtering, refer to Developer Guides - Practical Features | true |
| max_sentence_silence | Integer | No | Speech sentence breaking detection threshold. Silence longer than this threshold is considered as a sentence break. The valid parameter range is 200~1200. Unit: Milliseconds | sample_rate=16000:800 sample_rate=8000:250 |
| enable_words | Boolean | No | Whether to return word information, refer to Developer Guides - Basic Terms | false |
| hotwords_list | String | No | Hotwords list, effective only for the current connection. If both hotwords_list and hotwords_id parameters exist, hotwords_list will be used. Up to 100 groups/items can be uploaded at a time. refer to Developer Guides - Practical Features | None |
| hotwords_id | String | No | Hotwords ID, refer to Developer Guides - Practical Features | None |
| hotwords_weight | Float | No | Hotwords weight, the range of values [0.1, 1.0] | 0.4 |
| correction_words_id | String | No | Forced correction vocabulary ID, refer to Developer Guides - Practical Features Supports multiple IDs, separated by a vertical bar |;all indicates using all IDs. | None |
| forbidden_words_id | String | No | Forbidden words ID, refer to Developer Guides - Practical Features Supports multiple IDs, separated by a vertical bar |; all indicates using all IDs. | None |
| field | String | No | Field general: supports the sample_rate of 16000Hz call-center: supports the sample_rate of 8000Hz | None |
| audio_url | String | No | Returned audio format (stored on the platform for only 30 days) mp3: Returns a url for the audio in mp3 format pcm: Returns a url for the audio in pcm format wav: Returns a url for the audio in wav format | None |
| gain | Integer | No | Amplitude gain factor, range [1, 20], refer to Developer Guides - Practical Features 1 indicates no amplification, 2 indicates the original amplitude doubled (amplified by 1 times), and so on | sample_rate=16000:1 sample_rate=8000:2 |
| enable_save_log | Boolean | No | Provide log of audio data and recognition results to help us improve the quality of our products and services | true |
| duration | Integer | No | Maximum Audio Duration Input: Default value: 60s. Valid range: [60, 600], unit: second. | 60 |
| enable_spoken | Boolean | No | When enabled, the sentence information will increase the return of pronunciation. Note: This feature currently only supports Japanese and is not available for other languages. | false |
| enable_dynamic_break | Boolean | No | When enabled, it will adaptively adjust the sentence-breaking effect based on the speaking rate and the maximum silence duration parameter (max_sentence_silence). | false |
3.4 Example of Request
curl --location --request POST 'http://127.0.0.1:7100/stream/v1?lang_type=zh-cmn-Hans-CN&format=pcm&sample_rate=16000&enable_punctuation_prediction=true&enable_inverse_text_normalization=true' \
--header 'Content-Type: application/octet-stream' \
--data-binary '@audio.pcm'3.5 Response Results
The response results are located within the Body. The response result fields are as follows:
| Name | Type | Description |
|---|---|---|
| status | String | Service status code |
| message | String | Service status description |
| data | Object | |
| ├─task_id | String | Please record this value for troubleshooting |
| ├─result | String | Speech recognition result |
Successful Response
If the status field in the body is 000000, it indicates a successful response.
{
"status": "000000",
"message": "success",
"data": {
"task_id": "f71cba68-2399-4fcd-b754-40a0d2ff5b50",
"result": "外資不動産投資環境の改善"
}
}Error Response
Any status field in the body that is not 00000 is considered an error response. This field can be used as an indicator of whether the response was successful.