開発ガイド
1 基本用語
1.1 サンプリングレート(sample rate)
音声サンプリング率は、音声信号をサンプリングする回数を示しており、1秒間に何回サンプリングされるかを表しています。サンプリングレートが高いほど、音声のデータより詳しく保存され、もっと精度の高い認識率が期待されます。
弊社音声認識各サービスを使用する際には、パラメータとして音声のサンプリング率を指定し、実際に送信される音声のサンプリング率はパラメータ値と一致する必要があります。現在、音声認識の各サービスでは、では 16000 Hz、8000Hz のサンプリング率の音声のみサポートしています。
1.2 サンプルサイズ(sample size)
サンプルサイズは、音声の波動変化を評価するパラメータであり、音声ファイルを収集および再生する際に使用されるデジタル音声信号の二進制数です。弊社音声認識各サービスは、現在16ビットのサンプルサイズのみサポートしています。
1.3 音声チャンネル(sound channel)
チャンネルとは、録音または再生時に異なる空間位置で収集または再生される独立した音声信号を指します。したがって、チャンネル数は音声を録音する際の音源の数または再生時の対応するスピーカーの数を表します。現在、弊社音声認識の各サービスでは、録音ファイル書き起こしのみがモノラルと2チャンネル音声ファイルの認識をサポートしており、その他のサービスではモノラルのオーディオのみがサポートされています。
1.4 言語
現在、日本語、日英混合、英語、中国語、中英混合の言語をサポートしています。
1.5 中間結果と最終結果
ストリーミングインターフェイス(一発話認識WebSocketインターフェイス、リアルタイム音声認識)では、音声の入力に基づいてリアルタイムで結果が返されます。例えば、「今日の天気はいいね」という言葉では、認識しながらで次のような認識結果が生じる可能性があります:
てんき
天気が
天気がいい
天気がいいです。その中で、前三つは「中间結果」と呼ばれ、最後の一つは「最終結果」と呼ばれます。ストリーミング認識プロダクトの enable_intermediate_result パラメータを設定することで、中间結果を返すかどうかを制御できます。
1.6 セグメント情報
セグメンタ情報は、認識処理中でセグメント別の情報であり、現在セグメントのテキスト情報、開始時間、終了時間を含んでいます。リアルタイム音声認識サービスを使用する際には、セグメント情報を返すかどうかを指定できます。
| プロジェクト | 中間結果語情報 | 最終結果語情報 |
|---|---|---|
| 制御パラメータ | enable_intermediate_words | enable_words |
| 以下を含む:テキスト内容、開始時間、終了時間 | √ | √ |
| 以下を含む:語の種類 | √ | |
| 以下を含む:語の安定状態 | √ |
語の安定状態フィールドは、現在の語が中間結果の中で変化する可能性があるかどうかを示すために使用されます:真でない場合、この語は後続の中間結果で変化する可能性があることを示します。それ以外の場合、この語は既に安定し、変化しません。このフィールドは現在、以下の言語をサポートしています:中国語、中国語と英語の混合。(つまり、言語コードは zh で始まります)
1.7 逆テキスト正規化(ITN)
逆テキスト標準化(Inverse Text Normalization)は、音声認識結果の中の日時や数字などを慣用の形式で表示することを指します。例えば、以下のようになります:
| ITNがオフの場合 | ITNが有効の場合 |
|---|---|
| 二十パーセント | 20% |
| 千二百三十四円 | 1234円 |
| 四月三日 | 4月3日 |
ITNを有効にするかどうかを指定できます。
2 実用機能
2.1 テキスト正規化(ITN)
音声認識サービスを使用する際には、enable_inverse_text_normalization パラメータを設定することで、ITNを有効にするかどうかを指定できます。
2.2 単語
特定の人名、地名、製品名、会社名、または特定の分野の専門用語などについては、認識精度が低い場合があります。これらの専門用語については、手動で「単語」として追加することで、単語リスト内の単語認識精度を大幅に向上させることができます。
単語の構成:
- 日本語&日英混合の言語: 単語は単語セットの形式で設定されています。単語セットは「表記、読み、クラスコード」で構成されます。例:
早稲田大学,ワセダダイガク,0。- クラスはシステム設定値であり、呼び出し時には実際の状況に応じて選択してください。もし設定された単語セット内のクラスがシステム設定値と異なる場合、その単語セットはフィルタリングされます。
- 選択可能なクラスは次の通りです:
コード クラス 0 クラス指定無し 1 固有名詞 2 名前 3 名前(名) 4 駅名 5 地名 6 会社名 7 部署名 8 役職名 9 記号 10 括弧開き 11 括弧閉じ 12 元号
- 中国語&中英混合&英語:単語の形式で設定され、すなわち「表記」のみで構成されます。例:
汇演。
単語の追加/削除などの操作については、単語API を参照してください。単語登録 ページでもできます。単語を追加した後、認識時に hotwords_id パラメータを設定して単語 ID を渡すことで有効になります。
また、プラットフォームはリアルタイム単語機能をサポートしており、事前に単語 ID を作成する必要はありません。1回の接続/リクエスト中に単語リストhotwords_list パラメータを渡すことで、その回限り有効になります。使用後は削除されます。
- リアルタイム単語は 1 回あたり最大 100 個の単語または単語セットをアップロードできます。
- リアルタイム単語
hotwords_listと非リアルタイム単語hotwords_idを同時に使用する場合、リアルタイム単語が優先されます。 - 複数の単語セットをアップロードする場合、単語セットは
|で区切ります。例:早稲田大学,ワセダダイガク,0|新横浜,シンヨコハマ,5。
単語を使用する際には、単語の重み hotwords_weight を指定できます。重みが大きいほど、単語リスト内の単語認識精度が向上しますが、同時に他の類音語の誤認識の確率も増加しますので、重みパラメータの設定にはバランスを取る必要があります。
単語の自動抽出
単語辞書の作成や変更時に、単語の自動抽出機能を使用して、指定された文書内容から人名、地名、機関名などのキーワードを自動的に抽出し、単語のトレーニングに使用できます。
2.3 強制置換文字
ホットワード最適化で解決できない認識エラーについては、強制置換機能を使用して、指 定された間違った単語を手動で修正することができます。 例えば、音声認識サービスが 「5G 」を 「5時 」と誤って認識した場合、手動で強制置換ルール 「5時→5G 」を追加し、識別時に correction_words_id パラメータを設定することで、IDを渡して正しい識別を行うことができます。correction_words_idパラメータを設定することで、正しい識別を行うことができます。 単語登録 ページでは、強制置換文字を追加/削除することができます。
2.4 NG単語
直接表示したくない単語については、「NG単語」として追加することができる。forbidden_words_id パラメータを設定して、識別時にセンシティブワードのIDを渡すと、識別結果(中間および最終結果を含む)のセンシティブワードを指定した文字(デフォルトはアスタリスク *)に自動的に置き換えることができます。単語登録 ページでは、NG単語を追加/削除することができます。
2.5 言い淀みフィルター
会話表現でよく見られる「うん」「えー」「これ」などの言葉を、手動で言い淀みフィルター規則を追加して、認識時に enable_modal_particle_filter パラメーターを有効にしておくと、認識結果(最終結果のみ)にマッチした助詞が自動的に削除されます。単語登録 ページでは、言い淀みフィルター規則を追加/削除することができます。
注意
以上の機能の処理優先順位は以下の通りです:

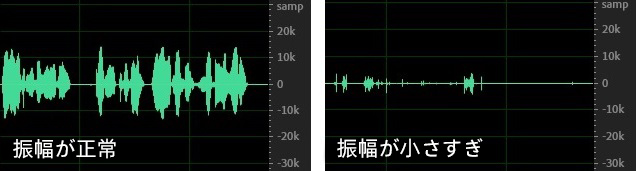
2.6 振幅
音声の振幅は音量の大きさを決定します。振幅が大きすぎるまたは小さすぎると、音声認識の効果が低下します。推奨振幅は±10k前後で、この範囲であれば音声認識の最適な効果を得ることができます。以下の図に示すように、左側は正常な振幅(±10k 前後の範囲)であり、右側は振幅が小さすぎる(±1k 前後の範囲)ため、右側の音声の認識効果は低下します。
振幅が小さい場合、次の2つの方法で改善できます。一つは録音方法の調整です。例えば、マイクとの距離、マイク/録音パラメータの設定など、元の音声層で音量が低い問題を解決します。もう一つは、音声認識サービスの振幅ゲインパラメータ gain を使用して、元の音声の振幅を増幅してから音声認識処理を行います。
2.7 録音ファイル書き起こしのファイルをアップロードする方法
録音ファイル書き起こしについて、音声URL設定と音声ファイルをアップロードの二つの方法をサポートできます。2つのアップロード方法は同時に使用できません。
2.8 録音ファイル書き起こしの関連機能:出力形式
録音ファイル書き起こしサービスについて、output パラメータを使用して出力形式を設定できます。
- 原稿形式:原稿のような長い文章では、話し言葉の間(ポーズ)を基準に通常の区切りを入れる。
- 字幕形式:字幕用に最適化された出力で、分割された文は短くなり、文末の句読点はなくなります。
2.9 録音ファイル書き起こしの関連機能:話者識別
音声チャンネルまたは話者ダイアライゼーションを使用して話者を区別することをサポートしています。2つの話者区別方法は同時に使用できません。
2.10 録音ファイル書き起こしの関連機能:キーワードの自動抽出
録音ファイルをアップロードする際に、キーワード数の上限を指定すると、システムは指定された数を超えない範囲でキーワードを自動抽出し、関連性や単語頻度に基づいて並べ替えることができます。この機能は中国語、中国語と英語の混合のみ対応しています。
2.11 録音ファイル書き起こしの関連機能:発話スピード計算
平均の発話スピードを自動計算します。日本語・中国語の場合、単位は字/分です。英語の場合、単位は単語/分です。
3 音声エンコーディング
現在、音声認識の各サービスは以下の音声エンコード形式をサポートしています。format フィールドを対応するエンコード形式に設定してください。
| エンコード形式 | 説明 | 一発話言認識、リアルタイム認識 | 録音ファイル書き起こし(通常版) | 録音ファイル書き起こし(急速版) |
|---|---|---|---|---|
| pcm | 非圧縮のサンプリングビット幅は16ビット、Little-Endianの音声です。一般的な非圧縮WAV形式(44バイト前のWAVヘッダーを含まない)に見られます。 | √ | √ | √ |
| wav | サンプリングビット幅が16ビットの音声です。 | √ | √ | √ |
| opus | OGG容器のOPUS形式で、framesizeは少なくとも60ミリ秒です。 | √ | √ | |
| mp3 | √ | √ | √ | |
| mp4 | √ | |||
| m4a | √ | √ | ||
| amr | √ | √ | ||
| 3gp | √ | |||
| aac | √ | √ |
4 言語サポート
言語コードは、language-variant-script-region形式を採用しています。
- language:言語(ISO 639-1)、全小文字、例:日本語はja、英語はen
- variant(オプション):発音または方言(ISO 639-3)、全小文字、例:中国語普通話はcmn、広東語はyue
- script(オプション):書記変種(ISO 15924)、頭文字が大文字、例:簡体字はHans、繁体字はHant
- region:言語の使用地理地域(ISO 3166)、全大文字、例:日本はJP、中国本土はCN
現在、音声認識の各サービスは以下の言語をサポートしています。lang_type(またはlangType、実際に使用するSDKによって決まります)フィールドを対応する言語コードに設定してください。
| 名前 | 言語コード | サンプリング率(Hz) | 一発話認識、リアルタイム音声認識 | 録音ファイル書き起こし(通常版&急速版) |
|---|---|---|---|---|
| 日本語 | ja-JP | 16k | √ | √ |
| 8k | √ | √ | ||
| 日英混合 | jaen-JP | 16k | √ | √ |
| 8k | √ | √ | ||
| 英語 | en-US | 16k | √ | √ |
| 8k | √ | √ | ||
| 中国語 | zh-cmn-Hans-CN | 16k | √ | √ |
| 8k | √ | √ | ||
| 中英混合 | zhen-cmn-Hans-CN | 16k | √ | √ |
| 8k | √ | √ |