Cloud API
1 機能紹介
長時間(37時間以内)の音声データストリームを識別することができ、会議のスピーチ、ビデオライブ配信などの長時間連続した識別シーンに適しています。
リアルタイム音声認識はWebSocket(ストリーミング)インターフェースのみ提供します。
2 サービスアドレス
wss://api.voice.dolphin-ai.jp/v1/asr/ws3 インタラクションフロー
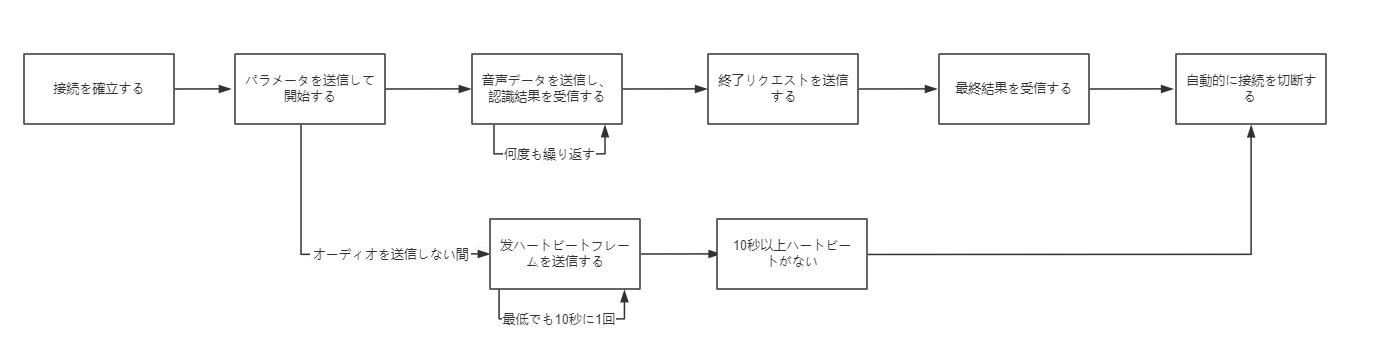
1.認証
クライアントはWebSocket接続を確立する際、次のリクエストヘッダを設定する必要があります:
| 名前 | タイプ | 必須 | 説明 |
|---|---|---|---|
| Authorization | String | はい | 標準HTTPヘッダーで、認証情報を設定します。形式は標準のBearer <Token>である必要があります(Bearerの後に空白があることに注意してください)。 |
認証関連の操作については、認証と承認を参照してください。
2.開始とパラメータの送信
クライアントからリクエストが送信され、サーバー側でリクエストの有効性が確認されます。その中で、リクエストメッセージにおいてパラメータの設定が必要になります。
パラメータの送信(headerオブジェクト):
| パラメータ | タイプ | 必須 | 説明 |
|---|---|---|---|
| namespace | String | 是 | メッセージが所属する名前空間:SpeechTranscriber リアルタイム音声認識の表示 |
| name | String | 是 | イベント名:StartTranscription は開始フェーズを示します |
パラメータの送信(payloadオブジェクト):
| パラメータ | タイプ | 必須 | 説明 | デフォルト値 |
|---|---|---|---|---|
| lang_type | String | はい | 言語オプション、開発ガイド-言語サポートを参照してください | 必須 |
| format | String | いいえ | 音声エンコード形式、開発ガイド-音声エンコードを参照してください | pcm |
| sample_rate | Integer | いいえ | 音声サンプルレート、開発ガイド-基本用語を参照してください sample_rate=「8000」の場合 fieldパラメータ・フィールドが必須で、かつfield=「call-center」 | 16000 |
| enable_intermediate_result | Boolean | いいえ | 中間認識結果を返すかどうか | true |
| enable_punctuation_prediction | Boolean | いいえ | 後処理で句読点を追加するかどうか | true |
| enable_inverse_text_normalization | Boolean | いいえ | 後処理でITNを実行するかどうか、開発ガイド-基本用語を参照してください | true |
| max_sentence_silence | Integer | いいえ | 音声センテンスの静寂検出しきい値、静寂時間がこのしきい値を超えるとセンテンスが切り替えられます。有効なパラメータ範囲は200~1200で、単位はミリ秒です | sample_rate=16000:800 sample_rate=8000:250 |
| enable_words | Boolean | いいえ | 単語情報を返すかどうか、開発ガイド-基本用語を参照してください | false |
| enable_intermediate_words | Boolean | いいえ | 中間結果の単語情報を返すかどうか、開発ガイド-基本用語を参照してください | false |
| enable_modal_particle_filter | Boolean | いいえ | 語気詞フィルタを有効にするかどうか、開発ガイド-基本用語を参照してください | true |
| hotwords_list | List<String> | いいえ | 一度限り有効な単語リスト、本接続中のみ有効ですhotwords_id と同時に存在する場合は、hotwords_list が優先されます。一度に最大 100 個まで提供可能です。詳細は開発ガイド-実用的な機能を参照してください | 無し |
| hotwords_id | String | いいえ | 単語ID、開発ガイド-実用機能を参照してください | 無し |
| hotwords_weight | Float | いいえ | 単語ウェイト、値の範囲[0.1, 1.0] | 0.4 |
| correction_words_id | String | いいえ | 強制置換単語庫ID、参照開発ガイド-実用機能 複数の強制置換単語庫IDを使用することができ、各IDは縦線 |で区切られます;all は全ての強制置換単語庫IDを使用することを意味します | 無し |
| forbidden_words_id | String | いいえ | NG単語ID、参照開発ガイド-実用機能 複数のNG単語IDを使用することができ、各IDは縦線 |で区切られます;all は全てのNG単語IDを使用することを意味します | 無し |
| field | String | いいえ | 分野 一般:general (サポートサンプルレート16000Hz) コールセンター:call-center (サポートサンプルレート8000Hz) | 無し |
| audio_url | String | いいえ | 戻り音声のフォーマット(プラットフォームでは30日間のみ保存) mp3:mp3形式の音声リンクを返す pcm:pcm形式の音声リンクを返す wav:wav形式の音声リンクを返す | 無し |
| connect_timeout | Integer | いいえ | 接続タイムアウト(秒)、範囲:5-60 | 10 |
| gain | Integer | いいえ | 振幅増幅係数を表し、範囲[1, 20]、開発ガイド-実用機能を参照 1は拡大しないことを示し、2は元の振幅の2倍(拡大1倍)を示し、以下同様 | sample_rate=16000:1 sample_rate=8000:2 |
| user_id | String | いいえ | ユーザーが定義した情報で、応答メッセージにそのまま返され、最大36文字までです | 無し |
| enable_lang_label | Boolean | いいえ | 言語を切り替える際に、認識結果に言語ラベルを返す:現在は日英混合、中英混合言語のみ対応しています。注意:この機能を有効にすると、言語切り替え時に応答の遅延が発生します | false |
| paragraph_condition | Integer | いいえ | 同じ speakerid 内で設定された文字数に達したら、次の文で新しい段落番号を返す:範囲[100, 2000]、範囲外の値はこの機能を無効化します | 0 |
| enable_save_log | Boolean | いいえ | 音声データと認識結果のログを提供して、弊社が製品とサービスの質を向上させるために使用することは可能ですか | true |
| enable_spoken | Boolean | いいえ | 有効にすると、文の情報に読み方が返却されます。注意:現在、本機能は日本語のみに対応しており、他の言語には対応していません。 | false |
| enable_dynamic_break | Boolean | いいえ | 有効にすると、話速および最大無音時間パラメータ(max_sentence_silence)に基づき、文の切れ目が動的に最適化されます。 | false |
| enable_speaker_label | Boolean | いいえ | リアルタイム話者識別を有効にしますか。有効にすると、単語情報に label タグが返され、話者情報を表示するために使用されます。 注意:この機能は単語情報の返却パラメータが有効になっている場合にのみ有効です。 中間結果の単語情報パラメータ:enable_intermediate_words。 最終結果の単語情報パラメータ:enable_words。 | false |
送信例:
{
"header": {
"namespace": "SpeechTranscriber",
"name": "StartTranscription"
},
"payload": {
"lang_type": "ja-JP",
"format": "pcm",
"sample_rate": 16000,
"enable_words":true
}
}返信パラメータ(headerオブジェクト):
| パラメータ | タイプ | 説明 |
|---|---|---|
| namespace | String | メッセージが所属する名前空間:SpeechTranscriber リアルタイム音声認識の表示 |
| name | String | イベント名:TranscriptionStarted は開始フェーズを示します |
| status | String | ステータスコード |
| status_text | String | ステータスコード説明 |
| task_id | String | タスクのグローバルユニークIDを記録して問題の解決に役立ててください |
返信例:
{
"header":{
"namespace": "SpeechTranscriber",
"name": "TranscriptionStarted",
"status": "000000",
"status_text": "success",
"app_id": "2362af9b-7302-4e07-89c5-oc5ac0358b8a",
"task_id": "ffae0288-eb2c-4u58-9482-a04c96d291a9",
"message_id": "b8ba637e-289c-4947-a303-88a283e7b4aa"
},
"payload":{
"index":0,
"time":0,
"begin_time":0,
"speaker_id":"",
"result":"",
"words":null
}
}3.送信音声データ、認識結果の受信
音声データを繰り返し送信し、継続的に認識結果を受信します。7680 Byteが推奨されるデータパケットサイズです。
リアルタイム音声認識サービスのインテリジェントな文切断機能により、文の始まりと終わりが判断され、結果のイベントで表示されます。 SentenceBegin 、 SentenceEnd イベントはそれぞれの文の開始と終了を示します,TranscriptionResultChanged イベントは文の中間の認識結果を示します。
SentenceBegin イベント
SentenceBegin イベントは、サーバーが一つの文の開始を検出したことを示しています。
返信パラメータ(headerオブジェクト):
| パラメータ | タイプ | 説明 |
|---|---|---|
| namespace | String | メッセージが所属する名前空間,SpeechTranscriber リアルタイム音声認識の表示 |
| name | String | メッセージ名前,SentenceBegin は一つの文の始まりを示します |
| status | Integer | 状態コードは、リクエストが成功したかどうかを示しており、サービス状態コードを参照してください |
| status_text | String | ステータスメッセージ |
| app_id | String | アプリケーションID |
| task_id | String | タスクのグローバルユニークIDは、問題を特定するためにこの値を記録してください |
| message_id | String | このメッセージのID |
返信パラメータ(payloadオブジェクト):
| パラメータ | タイプ | 説明 |
|---|---|---|
| index | Integer | 文の番号は、1から増加します |
| time | Integer | 現在処理中の音声の持続時間、ミリ秒単位 |
| begin_time | Integer | 現在の文に対応する SentenceBegin イベントの時間、ミリ秒単位 |
| speaker_id | String | 発話者番号は、以下の「追加機能-発話者番号」セクションを参照してください |
| result | String | 認識結果は、時々空になる可能性があります |
| confidence | Float | [0, 1]の範囲で、現在の結果の信頼度 |
| words | Dict[] | 常に空です |
返信例:
{
"header": {
"namespace": "SpeechTranscriber",
"name": "SentenceBegin",
"status": "000000",
"status_text": "success",
"app_id": "2362af9b-7302-4e07-89c5-oc5ac0358b8a",
"task_id": "ffae0288-eb2c-4u58-9482-a04c96d291a9",
"message_id": "82e8b452-47a8-44ab-aa68-dd51ef803d89"
},
"payload": {
"index": 1,
"begin_time": 2640,
"time": 3280,
"speaker_id": "",
"result": "天",
"words": []
}
}TranscriptionResultChanged イベント
認識結果は「中間結果」と「最終結果」に分けられ、詳細な説明については開発ガイド-基本用語セクションを参照してください。
TranscriptionResultChanged イベントは認識結果が変化したこと、つまり一つの文の中間結果を示します。。
-
enable_intermediate_resultをtrueに設定すると、サーバーは連続して複数回TranscriptionResultChangedメッセージを返し、つまり認識の中間結果です。 -
enable_intermediate_resultをfalse,に設定すると、このステップでサーバーは何もメッセージを返しません。
SentenceEnd イベントに対応する結果を最終認識結果として扱ってください。返信パラメータ(headerオブジェクト):
ヘッダーオブジェクトのパラメータは上記の表(SentenceBeginイベントヘッダーオブジェクトの戻り値パラメータ)と同じです, name は TranscriptionResultChanged で、文の中間認識結果を示します。
返信パラメータ(payloadオブジェクト):
| パラメータ | タイプ | 説明 |
|---|---|---|
| index | Integer | 文の番号は、1から始まります |
| time | Integer | 現在処理中の音声の持続時間は、ミリ秒単位です |
| begin_time | Integer | 現在の文に対応するSentenceBeginイベントの時間は、ミリ秒単位です |
| result | String | 現在の文の認識結果 |
| confidence | Float | [0, 1]の範囲で、現在の結果の信頼度。 |
| words | Dict[] | この文の中間結果の単語情報enable_intermediate_words を true に設定するときだけ結果が返します |
その中で、中間結果の単語情報の words オブジェクト:
| パラメータ | タイプ | 説明 |
|---|---|---|
| word | String | テキスト |
| start_time | Integer | 単語の開始時間、ミリ秒単位 |
| end_time | Integer | 単語の終了時間、ミリ秒単位 |
| confidence | Float | [0, 1]の範囲で、現在の結果の信頼度。 |
| label | String | 話者番号、speaker_1 から順次増加します。同じ label の場合、同一話者を示していますenable_speaker_label を true に設定するときだけ結果が返します |
返信例:
{
"header": {
"namespace": "SpeechTranscriber",
"name": "TranscriptionResultChanged",
"status": "000000",
"status_text": "success",
"app_id": "2362af9b-7302-4e07-89c5-oc5ac0358b8a",
"task_id": "ffae0288-eb2c-4u58-9482-a04c96d291a9",
"message_id": "1814d9f6-12da-44c1-8db5-ddc775773b85"
},
"payload": {
"index": 1,
"begin_time": 2640,
"time": 3920,
"speaker_id": "",
"result": "天気が",
"words": [
{
"word": "天気",
"start_time": 2700,
"end_time": 3320,
"confidence": 0.96875696,
"label": "speaker_1"
},
{
"word": "が",
"start_time": 3450,
"end_time": 4090,
"confidence": 0.87596966,
"label": "speaker_1"
}
]
}
}SentenceEnd イベント
SentenceEnd イベントはサーバーが一つの文の終わりを検出し、その文の最終認識結果を付加して返します。
返信パラメータ(headerオブジェクト):
ヘッダーオブジェクトのパラメータは上記の表(SentenceBeginイベントヘッダーオブジェクトの戻り値パラメータ)と同じです。nameはSentenceEndで、文の終わりを認識したことを示します。
返信パラメータ(payloadオブジェクト):
| パラメータ | タイプ | 説明 |
|---|---|---|
| index | Integer | 文の番号は、1から始まります |
| time | Integer | 現在処理中の音声の持続時間は、ミリ秒単位です |
| begin_time | Integer | 現在の文に対応するSentenceBeginイベントの時間は、ミリ秒単位です |
| result | String | 現在の認識結果 |
| confidence | Float | [0, 1]の範囲で、現在の結果の信頼度 |
| words | List<Word> | この文の単語情報enable_words を true に設定するときだけ結果が返します |
その中で、単語情報のwordsオブジェクト:
| パラメータ | タイプ | 説明 |
|---|---|---|
| word | String | テキスト |
| start_time | Integer | 単語の開始時間、ミリ秒単位 |
| end_time | Integer | 単語の終了時間、ミリ秒単位 |
| type | String | タイプnormal は通常のテキストを示し、forbidden は NG 単語を示し、modal は言い淀みを示し(enable_modal_particle_filter を true に設定すると、このタイプは返されません)、punc は記号を示します |
| confidence | Float | [0, 1]の範囲で、現在の結果の信頼度 |
| label | String | 話者番号、speaker_1 から順次増加します。同じ label の場合、同一話者を示していますenable_speaker_label を true に設定するときだけ結果が返します |
返信例:
{
"header": {
"namespace": "SpeechTranscriber",
"name": "SentenceEnd",
"status": "000000",
"status_text": "success",
"app_id": "2362af9b-7302-4e07-89c5-oc5ac0358b8a",
"task_id": "ef81e8a0-953b-4793-bf5b-f98323360936",
"message_id": "e7c4b784-897a-4374-ba7b-696f62fd5d29"
},
"payload": {
"index": 1,
"begin_time": 2640,
"time": 6965,
"result": "天気がいいから、散歩しましょう。",
"words": [
{
"word": "天気",
"type": "normal",
"start_time": 2700,
"end_time": 3320,
"confidence": 0.96875696,
"label": "speaker_1"
},
{
"word": "が",
"type": "normal",
"start_time": 3450,
"end_time": 4090,
"confidence": 0.87596966,
"label": "speaker_1"
},
{
"word": "いい",
"type": "normal",
"start_time": 4090,
"end_time": 4480,
"confidence": 0.97566869,
"label": "speaker_1"
},
{
"word": "から",
"type": "normal",
"start_time": 4480,
"end_time": 4630,
"confidence": 0.98766965,
"label": "speaker_1"
},
{
"word": "、",
"type": "punc",
"start_time": 4680,
"end_time": 4680,
"confidence": 1,
"label": "speaker_1"
},
……略……
]
}
}追加機能
以下の追加機能は、リアルタイムの音声認識のみで利用可能です。
強制的な文切断
音声データを送信する過程で、SentenceEndイベントを送信すると、サーバーは現在の位置で強制的に文切断処理を行います。サーバーが文切断処理を行った後、クライアントはSentenceEndメッセージを受信し、その文の最終認識結果を含んでいます。
送信例:
{
"header": {
"namespace": "SpeechTranscriber",
"name": "SentenceEnd"
}
}4. 接続を維持する(ハートビートメカニズム)
音声を送信していない状態では、10秒以内に少なくとも1回ハートビートパケットを送信する必要があり、そうしないと自動的に接続が切断されます。クライアントには、8秒に1回の送信を推奨します。
送信例:
{
"header":{
"namespace":"SpeechTranscriber",
"name":"Ping"
}
}返信例:
{
"header": {
"namespace": "SpeechTranscriber",
"name": "Pong",
"status": "000000",
"status_text": "success",
"app_id": "f600aa9a-b117-4c62-ab7c-c7d9e6713a6f",
"task_id": "c7dd0acd-b47c-4ea7-a772-3d2cae15dbf2",
"message_id": "f013e785-238e-402d-ad60-81cd59566391"
},
"payload": {
"index": 0,
"begin_time": 0,
"time": 0,
"speaker_id": "",
"result": "",
"words": null
}
}10秒間にサーバーに何らかのデータが送信されない場合、サーバーはエラーメッセージを返して自動的に接続を切断します。
5.音声認識を停止して最終結果を取得する方法
クライアントはリアルタイム音声認識を停止するリクエストを送信し、サーバーに音声データの送信が終了し、音声認識を停止することを通知します。サーバーは最終的な認識結果を返し、自動的に接続を切断します。
パラメータの送信(headerオブジェクト):
| パラメータ | タイプ | 説明 |
|---|---|---|
| namespace | String | メッセージが属する名前空間です。SpeechTranscriberはリアルタイム音声認識を示します |
| name | String | メッセージ名。StopTranscriptionはリアルタイム音声認識を停止することを示します |
送信例:
{
"header": {
"namespace": "SpeechTranscriber",
"name": "StopTranscription"
}
}返信パラメータ(headerオブジェクト):
| パラメータ | タイプ | 説明 |
|---|---|---|
| namespace | String | メッセージが属する名前空間です。SpeechTranscriberはリアルタイム音声認識を示します |
| name | String | メッセージ名。TranscriptionCompletedは認識完了を示します |
| status | Integer | 状態コードは、リクエストが成功したかどうかを示します。サービスの状態コードを参照してください |
| status_text | String | 状態メッセージ |
| app_id | String | アプリケーションID |
| task_id | String | タスク全体で一意のIDです。この値を記録しておいて、問題のトラブルシューティングを容易にします |
| message_id | String | このメッセージのID |
戻りパラメータ(ペイロードオブジェクト):SentenceEndイベントのフォーマットと同じですが、result、wordsフィールドは空になる可能性があります。
返信例:
{
"header": {
"namespace": "SpeechTranscriber",
"name": "TranscriptionCompleted",
"status": "000000",
"status_text": "success",
"app_id": "2362af1b-7362-4e07-89c5-cc5ac0358b8a",
"task_id": "ef81e8a0-953b-4793-bf5b-f98323360936",
"message_id": "b272fe57-ec84-4b8d-b567-fdbffc0ca86a"
},
"payload": {
"index": 0,
"begin_time": 0,
"time": 0,
"speaker_id": "",
"result": "",
"words": []
}
}